先週末にサシシさん(@sashishi_EN)と🍣オフをしてたときに、「Spritz、Kindleのワードランナーのように視点を固定して動画の字幕を読めたら便利だと思うんですよ」という話をしてもらって、僕も興味があったのでPythonで実装してみた。
動いているところ
テキストストリーミングでAnime(POC) pic.twitter.com/IMCz9Bx6gd
— るびゅ (@ruby_U) 2020年12月6日
テキストストリーミングというらしい。概念は知ってたけど名前は知らなかった。
やってること
字幕のフォーマットについては動画コンテンツで英語学習をしているとなぜか詳しくなるので皆さんよくご存知だとは思うんですが、例えばassフォーマットでは次のようにスタイルとイベントで字幕が構成されています。
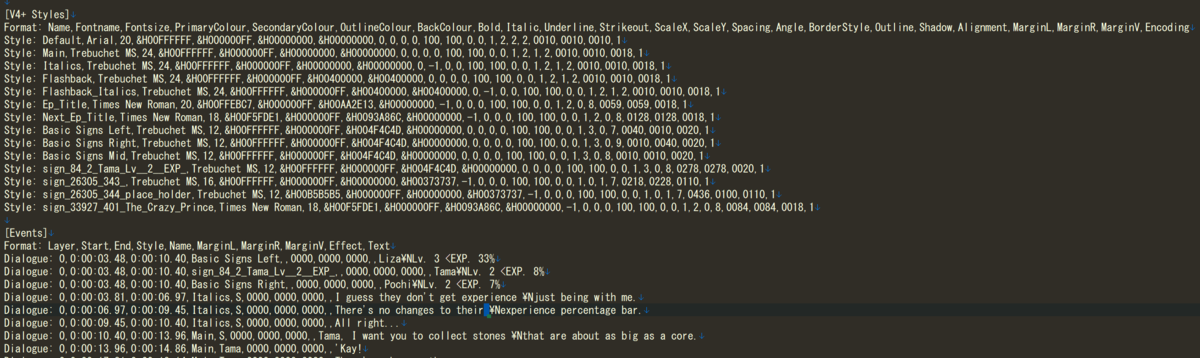
例えば次のようなイベントを
Dialogue: 0,0:00:10.40,0:00:13.96,Main,S,0000,0000,0000,,Tama, I want you to collect stones \Nthat are about as big as a core.
このように単語ごとに分割できればやりたいことはひとまず達成できます。
Dialogue: 0,0:00:10.40,0:00:10.63,Main,S,0,0,0,,Tama, Dialogue: 0,0:00:10.63,0:00:10.87,Main,S,0,0,0,,I Dialogue: 0,0:00:10.87,0:00:11.11,Main,S,0,0,0,,want Dialogue: 0,0:00:11.11,0:00:11.34,Main,S,0,0,0,,you Dialogue: 0,0:00:11.34,0:00:11.58,Main,S,0,0,0,,to Dialogue: 0,0:00:11.58,0:00:11.82,Main,S,0,0,0,,collect Dialogue: 0,0:00:11.82,0:00:12.06,Main,S,0,0,0,,stones Dialogue: 0,0:00:12.06,0:00:12.29,Main,S,0,0,0,,that Dialogue: 0,0:00:12.29,0:00:12.53,Main,S,0,0,0,,are Dialogue: 0,0:00:12.53,0:00:12.77,Main,S,0,0,0,,about Dialogue: 0,0:00:12.77,0:00:13.01,Main,S,0,0,0,,as Dialogue: 0,0:00:13.01,0:00:13.24,Main,S,0,0,0,,big Dialogue: 0,0:00:13.24,0:00:13.48,Main,S,0,0,0,,as Dialogue: 0,0:00:13.48,0:00:13.72,Main,S,0,0,0,,a Dialogue: 0,0:00:13.72,0:00:13.95,Main,S,0,0,0,,core.
データとして開始と終了のタイムスタンプがあるので、これも単語の数で割って等分に割り当てる必要があります。
[Events] Format: Layer,Start,End,Style,Name,MarginL,MarginR,MarginV,Effect,Text
実装(ライブラリ調べたりしながら1時間)
!pip install ass
import ass import re import copy def split_text_to_words(text): t = re.sub(r"(\\n|\\N)", " ", text) return re.split(r"\s+", t) def split_event(ev): words = split_text_to_words(ev.text) if len(words) == 0: return [] duration = ev.end - ev.start dpw = duration / len(words) split_events = [] for i, word in enumerate(words): ev2 = copy.deepcopy(ev) ev2.text = word ev2.start = ev.start + (dpw * i) ev2.end = ev2.start + dpw split_events.append(ev2) return split_events with open("in.ass", encoding='utf_8_sig') as in_f: doc = ass.parse(in_f) split_events = [] for ev in doc.events: events = split_event(ev) split_events.extend(events) doc.events.clear() doc.events.extend(split_events) with open("out.ass", "w", encoding='utf_8_sig') as out_f: doc.dump_file(out_f)
ぱっと思いついた残タスク
- 単語が表示されている時間は揃えたほうがよさそうな?
- テキストストリーミングに変換すべきところとそうでないところがありそう
- タグを残しつつ分割しなければいけない…?
- サシシさんへの引き継ぎ😊